War Stories: Proxy ARP Auto-Configuration
This article is Part 5 in a 12-Part Series.
- Part 1 - War Stories: Loops that Permanently Broke the Network
- Part 2 - War Stories: Switches Lying about Duplex Mismatches
- Part 3 - War Stories: Check Point Meltdown
- Part 4 - War Stories: Dual-Vendor Firewall Strategy
- Part 5 - This Article
- Part 6 - War Stories: Gratuitous ARP and VRRP
- Part 7 - War Stories: Cursed VLANs
- Part 8 - War Stories: Unix Security
- Part 9 - War Stories: ITIL Process vs Practice
- Part 10 - War Stories: Closing out Projects
- Part 11 - War Stories: Backup NICs, DNS and AD
- Part 12 - War Stories: Always Check Your Inputs
Back to Networking War Stories: This time it’s proxy ARP, Check Point, and more admissions that just occasionally, the firewall is actually at fault. This time I got caught out by proxy ARP configuration. Here’s what happened:
(Before starting, if you don’t understand the use of Proxy ARP and NAT, it might be worth reading this post first: Proxy ARP sucks).
The Network
We had a router (R1) sitting in front of a Check Point cluster (FW1-A and FW1-B), running on Nokia IPSO. VRRP was used for failover between the firewalls:
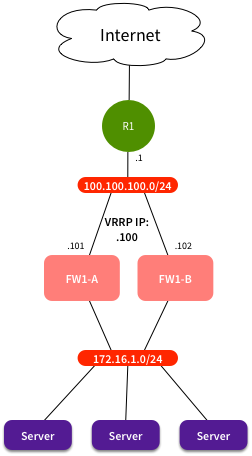
Most servers were statically NATted, in the range 200.200.200.0/24. There was a static route on R1 for that range that looked like this:
1
ip route 200.200.200.0 255.255.255.0 100.100.100.100
This was all working as expected. No proxy ARP required, because routing took care of it.
The Problem
When configuring NAT on objects in Check Point, there’s a few different ways of doing it. One method is to configure manual NAT rules. These rules are configured as a table, mapping original to NATted IPs (and/or ports). Another method is to configure Automatic NAT rules, on the object itself. There you configure it to statically NAT, to hide NAT behind a specific IP, or to hide NAT behind the firewall.
We had a couple of servers that would only ever need outbound access, so instead of wasting public IP space, we set them to automatically hide behind the firewall. This should hide the devices behind the firewall cluster public IP - 100.100.100.100 in this case.
The rules were configured, and all appeared to be well. Traffic was passed as expected, and NAT was working properly.
But then sometimes it didn’t. Or worse, it would ‘sort of’ work. Connectivity from those servers to external destinations was intermittent, sometimes working, sometimes not. A bit of bouncing back and forth, and the demand came “Reboot the firewall - switch traffic to FW1-B.” “Why?” “Well, just because it’s sometimes been flaky in the past, so just do it.”
I couldn’t see why this would help, since everything should be the same on the secondary firewall. Same policy, same hardware, same patch levels. Fine, I’ll do it, just to shut people up.
Ah crap. After using VRRP to switch traffic across to FW1-B, rebooting FW1-A, and making it VRRP master again, it all worked. Hmmm. Didn’t expect that.
When you’re always trying to defend the firewalls, it’s quite galling to have it proven that the problem is indeed the firewall.
What Was Going On?
Looking around, I saw some “Packet out of state” messages in the FW1-B logs. Why would that firewall be processing packets? Shouldn’t they all be going via FW1-A? Then when I dug further, I found this on the R1 ARP table:
1
2
3
4
5
6
R1#sh ip arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 100.100.100.100 0 bbbb.bbbb.bbbb ARPA FastEthernet0/0
Internet 100.100.100.101 0 aaaa.aaaa.aaaa ARPA FastEthernet0/0
Internet 100.100.100.102 0 bbbb.bbbb.bbbb ARPA FastEthernet0/0
R1#
What the hell’s going on there? Why is traffic for the virtual IP being forwarded to the real MAC of the standby firewall? Why isn’t R1 getting the VRRP MAC via ARP? It should be using 0000.5e00.0101.
Checking on FW1-B, the ARP table showed that it was publishing a proxy ARP entry for the VRRP IP. But why? It wasn’t configured anywhere in the IPSO configuration. And here’s where it got stranger: If we switched VRRP priorities, so FW1-B went to master, then went back to backup, the proxy ARP entry disappeared. That’s why things started working when we restarted FW1-A.
At that point it was all OK…until the next time policy was installed. Then the proxy ARP entry showed up again. It seemed that Check Point was automatically configuring proxy ARP entries that it thought the firewall needed. Why?
The Fix
Check Point has a global option for “Automatic Proxy ARP configuration.” This option will automatically add any proxy ARP entries that it thinks are required. It looks at all NAT entries, works out which ones are for attached networks, where no ARP entry currently exists. It then adds a proxy ARP entry for those IPs.
For most of our NAT rules, the IPs used were not in any directly attached network, therefore no proxy ARP was required. But for these hide NAT entries, it was in a directly attached network. On the VRRP Master, it already had an ARP entry for the VRRP IP, so no action was required. But on the Backup, it was not currently publishing an ARP entry - so Check Point automatically added one.
Switching the firewalls back and forth cleared this behaviour, and it was only re-applied at policy install time.
The fix was to disable Automatic Proxy Arp configuration. This is never required in a VRRP environment. If you ever needed proxy ARP, it would have to be manually added, to make sure the VRRP MAC was used, not the interface MAC. I believe Check Point changed the default policy in later versions.
We applied the fix, and after that, all was well. But people were still suspicious of that damn firewall…