War Stories: Gratuitous ARP and VRRP
This article is Part 6 in a 13-Part Series.
- Part 1 - War Stories: Loops that Permanently Broke the Network
- Part 2 - War Stories: Switches Lying about Duplex Mismatches
- Part 3 - War Stories: Check Point Meltdown
- Part 4 - War Stories: Dual-Vendor Firewall Strategy
- Part 5 - War Stories: Proxy ARP Auto-Configuration
- Part 6 - This Article
- Part 7 - War Stories: Cursed VLANs
- Part 8 - War Stories: Unix Security
- Part 9 - War Stories: ITIL Process vs Practice
- Part 10 - War Stories: Closing out Projects
- Part 11 - War Stories: Backup NICs, DNS and AD
- Part 12 - War Stories: Always Check Your Inputs
- Part 13 - Advertising Bogons (Or Was I?)
Continuing our theme of ARP-related war stories, here’s another ARP/switching behaviour I’ve come across. This particular problem didn’t result in any outages, but the network wasn’t working as well as it should have, and started flooding frames unexpectedly. Here’s what was going on:
The Network
Breaking the network down to its simplest level, it looked like this:
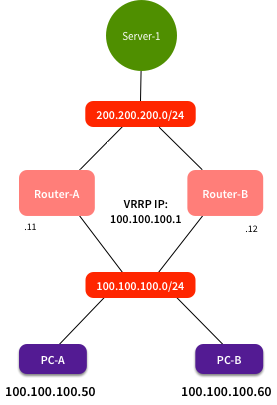
The two routers were a VRRP pair. Router-A was 100.100.100 .11, Router-B was 100.100.100.12, and the virtual IP was 100.100.100.1. These acted as a default gateway for the client LAN. PCs connected to the client LAN got their network configuration from DHCP, and set their default gateway to 100.100.100.1. Using this, they were able to get access to resources behind the routers, such as Server-1 at 200.200.200.200. All worked well.
Obviously there was a lot more to the network than what I’ve shown here, but it’s not important.
The Issue
I said it was working well - so what was wrong? One day I was using Wireshark to diagnose a network issue between PC-A and Server-1. I ran Wireshark on PC-A, with a capture filter of “host 200.200.200.200”. The packet flow looked something like this:
1
2
3
4
5
6
100.100.100.50 -> 200.200.200.200 SYN
200.200.200.200 -> 100.100.100.50 SYN, ACK
100.100.100.50 -> 200.200.200.200 ACK
100.100.100.60 -> 200.200.200.200 SYN, ACK
100.100.100.50 -> 200.200.200.200 PSH, ACK
100.100.100.60 -> 200.200.200.200 ACK
What’s going on there at lines 4 & 6? Occasionally I would see this:
1
2
3
4
5
6
7
aaaa.aaaa.aaaa -> ffff.ffff.ffff ARP Request: Who has 100.100.100.1? Tell 100.100.100.50
0000.5e00.0101 -> aaaa.aaaa.aaaa ARP Reply: 100.100.100.1 is at 0000.5e00.0101
100.100.100.50 -> 200.200.200.200 SYN
200.200.200.200 -> 100.100.100.50 SYN, ACK
100.100.100.50 -> 200.200.200.200 ACK
100.100.100.50 -> 200.200.200.200 PSH, ACK
200.200.200.200 -> 100.100.100.50 ACK
So sometimes I would see PC-B traffic, and sometimes not. What’s going on? I haven’t shown it here, but the destination MAC for PC-B -> Server-1 traffic was 0000.5e00.0101 - i.e. the MAC associated with the VRRP IP address. Why is my expensive switch acting like a hub and flooding frames? Surely it should have worked out which port the VRRP MAC is connected to? There’s traffic going through that system all the time, so surely the CAM tables won’t have aged out?
The Cause & The Solution
The problem here was that the routers don’t normally source traffic with the VRRP MAC. If Router-A is forwarding a packet from Server-1 to PC-B, it will set the source MAC to be its real MAC. When it sends out regular VRRP multicast packets, it will use the real MAC. So how can the switch learn where the VRRP MAC is currently connected to? It only learns it when a client sends an ARP request for 100.100.100.1, and the primary router responds. It learns that for a while, but the CAM table will age out quickly (typically 5 minutes), while client ARP caches might take 1 hour to timeout. When the CAM table doesn’t have an entry for a unicast address, the switch has no choice - it has to flood the frames out all ports. Ugly.
The fix in this case was to upgrade to new code Huawei had released, that included periodic gratuitous ARPs. Once every 60s, the primary router would send a gratuitous ARP reply, sourced from the VRRP MAC. These are also sent on VRRP failover, to update CAM tables. By sending out these gratuitous ARPs within the switch CAM table timeout window, it ensured the CAM table always had an entry for the VRRP MAC. No more flooding of unknown unicast frames.
This is one of the problems I like - you need to know the fundamentals of things like ARP, and CAM table behaviour. If you skipped that class, you’ll spend ages chasing down dead-ends. I don’t yet consider myself a Grumpy Old Man, but this is something all network engineers should understand. It’s not cutting edge or exciting, but then again it seems that so many of the latest SDN technologies seem to be built around dealing with L2-related issues.
Related Problems
I’ve seen this sort of thing come up in a couple of other places. One was with some Check Point firewalls, where our default firewall policy allowed the firewalls to send VRRP traffic, but crucially, it only let the real IPs send traffic. Nokia systems also send regular packets from the virtual IP + MAC, to update CAM tables. This got dropped by the outbound policy, so the switch never saw it, and never updated its CAM table. It only got updated when a client sent an ARP request. With a low number of clients on the network, it meant that there were regular periods where the switch was unnecessarily flooding frames.
More recently, it was in a network that looked like this:
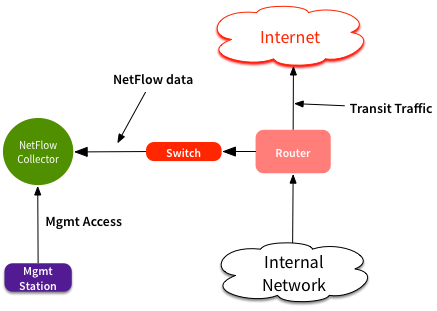
The Netflow collector has two interfaces - one for receiving NetFlow packets, and one for management. NetFlow traffic is all one-way UDP. The router sends NetFlow packets, and the collector never acknowledges it. Initial ARP requests update the CAM table, but again the CAM table expires long before the router ARP cache. Since the collector never sources any other frames out that interface, the switch doesn’t know where that MAC is, and starts flooding frames out all ports on that VLAN. Not an ideal situation if you’ve got high volumes of NetFlow traffic.
Pay Attention to Details
This is just another one of those situations where you should be paying attention to details. When you see something that doesn’t look quite right in a packet capture, investigate it, even if it’s not the main issue you’re dealing with right then. You never know what you’ll find.