War Stories: Dual-Vendor Firewall Strategy
This article is Part 4 in a 12-Part Series.
- Part 1 - War Stories: Loops that Permanently Broke the Network
- Part 2 - War Stories: Switches Lying about Duplex Mismatches
- Part 3 - War Stories: Check Point Meltdown
- Part 4 - This Article
- Part 5 - War Stories: Proxy ARP Auto-Configuration
- Part 6 - War Stories: Gratuitous ARP and VRRP
- Part 7 - War Stories: Cursed VLANs
- Part 8 - War Stories: Unix Security
- Part 9 - War Stories: ITIL Process vs Practice
- Part 10 - War Stories: Closing out Projects
- Part 11 - War Stories: Backup NICs, DNS and AD
- Part 12 - War Stories: Always Check Your Inputs
Networks of the early 2000s often used multiple firewall vendors. This was done with the best of intentions, but it could make troubleshooting far more complicated. Here’s a weird bug we came across with one firewall, that was obscured by data we saw on another firewall.
Dual-Vendor Good, Right? Maybe Not
Years ago, we used to believe in a “dual-vendor” firewall strategy. We were told to use two different brands of firewalls in front of our systems, the assumption being that if there were flaws in one, the other would protect us. The problem with this approach was that it assumed that the issues would be with the firewall software itself, not the configuration, or that the attacks were happening at a higher layer, and the firewall policy would make no difference. I believe it stemmed from some Check Point FTP handling flaws from the late 90s/early 2000s. We haven’t seen any really good firewall bypasses for a while, but this “best practice” persisted.
The problem with the dual-vendor approach is that inevitably the local staff will prefer one platform over the other, and will end up applying a simple policy to one firewall, and doing most enforcement on the other. One platform will get care, love and feeding, while the other will only have the minimum done to it. This really shows itself up when bugs strike - the unloved platform doesn’t have a good body of knowledge around detailed troubleshooting.
Thankfully these days are behind us, and we now tend to use one brand of firewall. Even Gartner caught up in 2012, publishing “One Brand of Firewall Is a Best Practice for Most Enterprises.”
Here’s a story where the dual-firewall strategy tripped us up, because we were so used to focusing on one platform, and ignoring the other.
Can’t Connect? Blame the Firewall
We were getting reports that an internal server couldn’t make HTTPS connections to an external server. It could make HTTP connections, but not HTTPS to some specific sites. Some worked, some didn’t. Surely it’s not a firewall problem? We used to tell admins “try using Telnet to connect to a remote port. If you get an immediate Reject, then it’s your app, not our firewall.” They tried, and they were finding their were quickly rejected, not suffering a slow timeout (as they would if our firewall dropped it). Case closed, right?
But the server team pointed out that they could connect to that remote webserver from other clients, in different parts of the network, or from home, etc. Hmmm.
This went back and forth for a few days, including bouncing back & forth with the remote server operator, until things came to a head on a Friday evening, and the boss demanded we all sit down together, and get it fixed.
Here’s the key elements of the network:
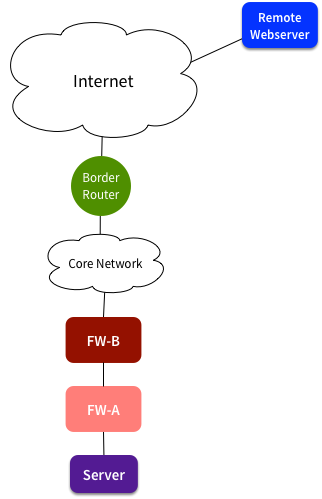
I’ve simplified the network, but the key parts are that there were two policy enforcement devices between our server and the Internet. We’d been focusing on firewall FW-A, as that’s where we applied our granular controls and made regular changes. It had also been a source of pain the past, and was often viewed with suspicion by people looking to blame something.
They say the packets don’t lie, so we turned to tcpdump. Running that on FW-A was pretty convincing. It showed a SYN leaving our server, NAT policies applied, a short delay, then a RST from the remote server. Case closed, surely? Don’t blame the firewall.
Investigating Deeper
It was now 6pm on Friday, and I wanted to go home. Hadn’t I proved it wasn’t the firewall? Can’t I go home now? Make the remote server team fix it.
But no, I wasn’t allowed to go. The remote team said “our firewall policy allows that traffic, and we can see a SYN come in, and we send a SYN/ACK back, but you never respond to it. Besides, lots of other people are connecting to this system - there’s something wrong with your network.”
Management made us dig deeper, so we kept looking. This time I grabbed a packet capture from a network tap at our network border. This showed something interesting: SYN traffic leaving our network, and a SYN/ACK coming back. No inbound RST. Where the hell was the RST coming from? Why wasn’t the SYN/ACK making it back to our server?
What was FW-B doing? It was from a different vendor, and had a coarser policy applied. It didn’t change much, and it had never given us much trouble. Its outbound policy was pretty simple - allow everything outbound, and dynamically allow the reply traffic. That was working fine for lots of other HTTP & HTTPS sites, surely it couldn’t be causing a problem?
Timing is Everything
I started looking closer at the exact sequence of timings. I realised that there was a 350ms gap between the SYN being sent, and the RST being received. Other successful connections had a shorter time between the SYN and SYN/ACK. Hmmm.
Digging into it further, I realised that FW-B must be generating a RST, if it thought that the connection was in SYNWAIT state for too long. The firewall was meant to allow 30s for these connections, but it was obviously applying a much shorter timeout, more like 300ms. For local systems, or quick-responding international systems, this was fine. But if the server was just a bit slower responding, such as for a remote SSL server, then FW-B kicked in and cut off the connection attempt.
The documentation said we could change the timeouts, but that made no difference. Not exactly a surprise, since it wasn’t like it was applying the default timeouts anyway. What can we do? At that point it was looking like a bug, but we couldn’t get vendor validation, and anyway, we weren’t going to be able to upgrade the system at 7pm on Friday evening.
We had to get it working somehow, so we ended up completely working around that feature. Instead of dynamically adding rules to allow reply traffic, we just changed it to allow all inbound established traffic. Not a stateful firewall anymore, but then we were doing that on FW-A - what value was FW-B adding, if it was only enforcing the same policy?
Wrap-up
A few lessons were learned, including:
- More systems means more complexity. More complexity means troubleshooting takes far longer.
- Don’t always be too sure of yourself. Be gracious when suggesting that it’s another team’s issue - it might turn out to actually be your fault.
- The packets don’t lie. But they’re like CCTV: They don’t always tell the WHOLE truth. Sometimes you need to capture packets from multiple locations to work out what’s really going on.