ScienceLogic Database HA & DR
Previously I’ve looked at the overall ScienceLogic architecture, and HA options for the Collectors and UI. This post looks at DR and HA options for the core Database layer - the heart of the ScienceLogic system.
HA vs DR
There’s a few different definitions of HA and DR. These definitions are used here:
-
High Availability - HA: Automatic synchronisation and failover between systems located at the same site. Automatically handles hardware or software failure on primary system.
-
Disaster Recovery - DR: Automatic data synchronisation between systems located at separate data centres. Manual failover required. Handles hardware or software failure of primary system, but requires manual intervention to initiate failover. The advantage of this setup is that it can withstand a total site failure.
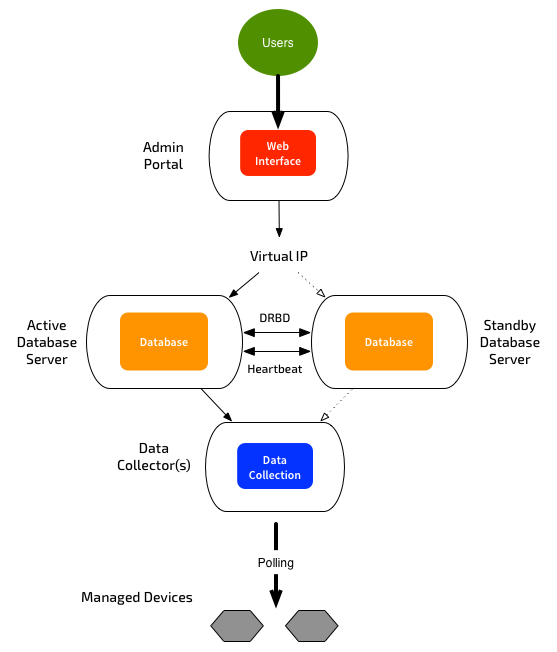
High Availability
You can configure multiple database servers at the same site, acting as an active/passive cluster. ScienceLogic uses DRBD for block-based replication between the database servers. A heartbeat network must exist between the servers. If ScienceLogic detects a failure, it will switch the secondary system to active, and will swing the virtual IP across to the secondary DB. This means that no re-configuration is required for the Admin Portals in the event of a failover.
Disaster Recovery
In this scenario, the databases are again replicated using DRBD, with DRBD proxy. There is no heartbeat network, and failover is manual. You run a script to promote the secondary system to master. You can also “demote” the primary system, and tell it to start replicating FROM the other system. Assuming you have identical hardware, there is no practical difference as to which system is the master - you can switch back and forth at will. Only the master system will talk to the collector systems. If you have a separate Admin Portal, it will need to be re-pointed to the new primary system, and/or DNS records updated.
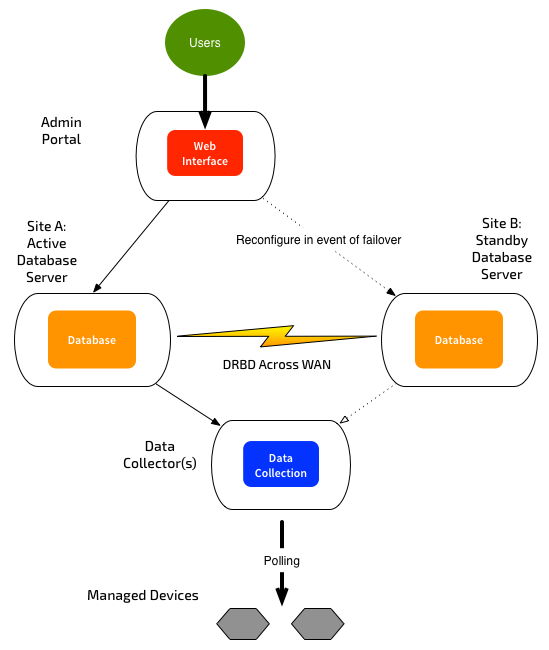
Using DRBD proxy can better handle slower/congested networks between the database servers, by providing some buffering.
DR also changes your backup policy options - you can execute a full backup from the secondary database server. Doing a full backup is an I/O intensive process, so running from the DR system makes sense - it has no impact on the user experience. Doing a full backup of the active system can cause some slow-down for the user.
Scaling
You’ll notice that all the variations only ever have one “active” database at any one time. All the processing is done on this system, with the results replicated to the other databases. You can scale out your Collectors or User Interface by adding more servers - but you can’t scale out the core database. Right now you have to scale up the database - ie. allocate more RAM/CPU/IOPS. This gets around the performance bottlenecks, but comes at a cost. Hopefully we’ll see some new architectures in future that will let us scale out this layer.
As always, you should read the official documentation for more information on all these configurations. HTML version, PDF version. Errors and omissions are mine.