ScienceLogic - Collector and UI HA
Earlier I looked at the basics of ScienceLogic EM7 architecture. I didn’t cover how to achieve HA or DR with ScienceLogic. The architecture offers a few options for doing this, at each of the three layers - Collectors, UI and DB. In this post I’ll cover some HA options for the Collectors and the UI.
Collector HA/DR
There are two types of Collectors - Data Collectors, and Message Collectors. Data Collectors do the active polling - e.g. WMI, SNMP, XML, ping, while Message Collectors do passive monitoring via syslog and SNMP traps.
Data Collectors
It’s pretty easy to achieve HA for Data Collectors. Data Collectors can be provisioned as part of a “Collector Group”. After that, you refer to the group, rather than the individual collector. You can have many collectors as you like in one group - presumably there is some maximum. Since collectors are virtual appliances, this means you can easily spin up more collectors if you need to better distribute your load.
When you add devices to ScienceLogic, you tell it what collector group you want to use to monitor the device. ScienceLogic will then automatically distribute devices across the collectors. You don’t have any control over this - the distribution is done automatically.
If a collector is unreachable, ScienceLogic will automatically re-assign those monitored devices across the remaining collectors. When the collector comes back online, it will automatically re-distribute the load. You can control the time delay before re-distributing load, or set it to Manual fail-back if you prefer. You can also set the maximum allowable number of failed collectors before ScienceLogic will stop monitoring altogether. You can add more collectors in future if you need to distribute your load further.
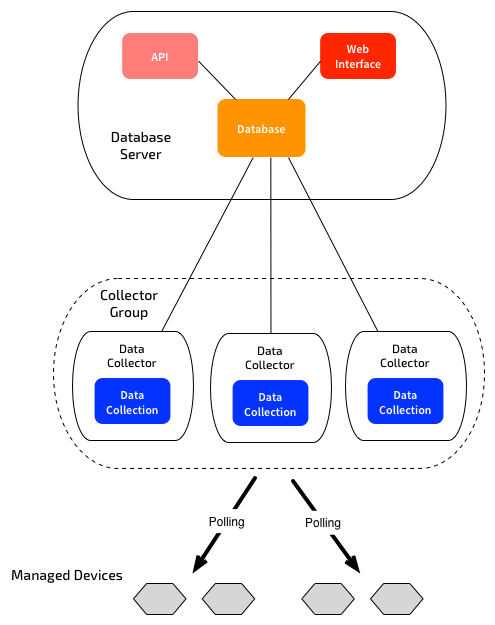
This system is easy to configure, and I’ve found that it works well in the Real World. Just make sure that all devices allow SNMP monitoring from ALL collector IP addresses. The only problem is that you can’t set a “preferred” collector - e.g. you may want to have a collector group that spans multiple data centers, but prefer to do the monitoring from the closest data collector to the monitored device. Unfortunately you can’t control that right now. Future release maybe?
Message Collectors
Message Collectors aren’t quite so elegant. The fundamental issue is that you need to configure a destination IP address for forwarding SNMP traps and syslog messages on all your monitored devices. But hang on, most systems let you configure multiple destinations for traps/syslogs, so can’t we just use that? Yes…but: If you build two Message Collectors, then define two syslog/trap destinations on all your devices, you’ll end up with duplicate messages in ScienceLogic. It doesn’t natively support an active/passive configuration for Message Collectors.
You’ve got a few options here:
- Put a load balancer in front of the message collectors, so that only one copy of the message gets sent, via either collector. The load balancer can then do failover if needed.
- Use iptables to block inbound syslog and SNMP traps on your secondary Message Collector. If you have to failover, manually update iptables to allow those messages.
- (Less plausible) Configure a single destination address on all managed systems. Use some orchestration tool (e..g Puppet) to force a destination IP change during failover.
The load balancer is probably the best option, but it may not always be possible
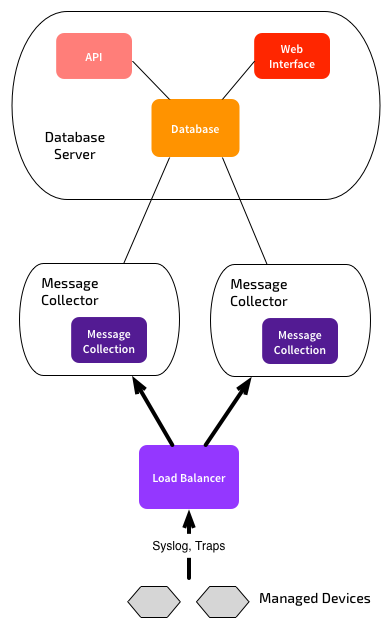
There is also one further wrinkle: If you have a single Data Collector, it can also act as a Message Collector. But if you need HA for your Data Collectors, you have to break the Message Collection functionality out onto a separate device.
UI - Web interface and API access
The web and API access components are also quite easy to configure for HA and DR. Neither of these pieces holds any data, and you can have as many active Admin Portals as you like. This can help with spreading load. You could use something like a Load-Balancer in front of a pair of Admin Portals for HA, and use DNS to switch to an Admin Portal at a secondary site for DR:
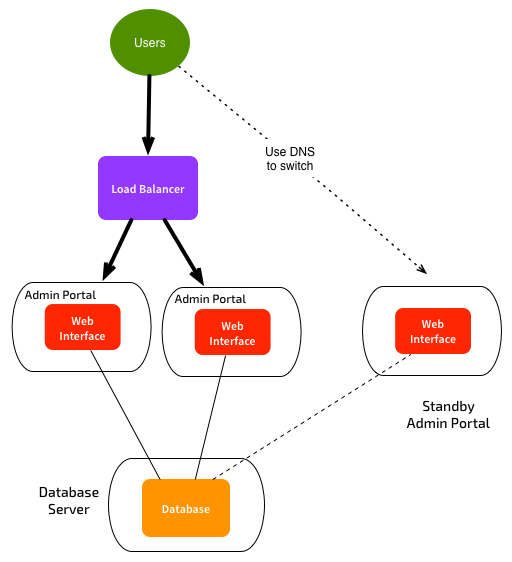
More information on these configurations is in the official documentation (HTML version, PDF version). Next post I’ll cover some HA + DR options for the Database layer. Scaling out load is a bit trickier at that level.