Network Monitoring Design Choices - Polling Distribution
Network monitoring systems poll devices periodically, and then calculate average rates across the poll interval. Selecting the right polling interval is important - too frequently, and low-end devices can’t keep up. Too long an interval, and we might miss spikes, will lose detail, and will increase our time to detect & respond to incidents. We may choose to sample some specific values, or devices, more frequently - e.g. 1-minute status polling of our core devices, 5-minute polling for edge devices. But what about the collector - how does it decide when to run those polls?
We have a number of values being polled, across a number of devices, with varying frequency. How do you design your collection processes? Do you dynamically spread the polling to even out the load? After all, the users are only specifying the frequency (every x minutes), not the exact time when the poll runs. Or do you use “round” numbers, and run all your 5-minute polls at 5, 10, 15… minutes past the hour, and your 15-minute polls at 00, 15, 30, 45 minutes past the hour? Won’t that cause peaks and troughs? Does it really matter?
Let’s look at the Network Data
Take a look at these two images. They show network utilisation for a couple of different network monitoring systems, recorded over 1 day. Both are monitoring small-medium networks - a few hundred systems. The first one is from a ScienceLogic Data Collector. Note the regular peaks? So far as I can tell, these are from some of the less-frequently polled metrics overlapping with regularly polled metrics. There’s also a couple of larger peaks, from some daily discovery processes:
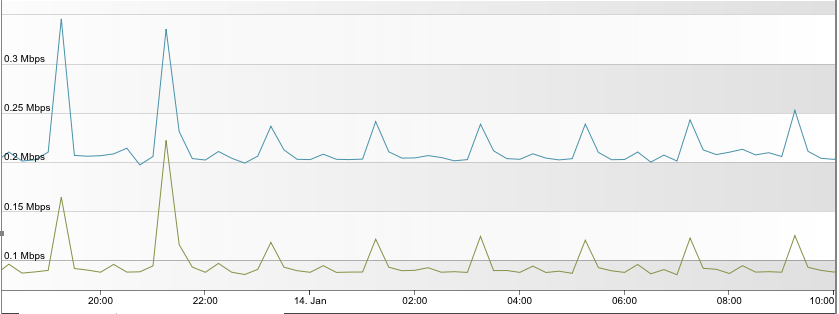
ScienceLogic Data Collector Network Usage over 1d
Now look at this graph, showing bandwidth utilisation for an HP SIM server. Note how it’s much flatter, apart from a couple of peaks (I haven’t checked, but it’s probably a daily discovery, and a backup process):
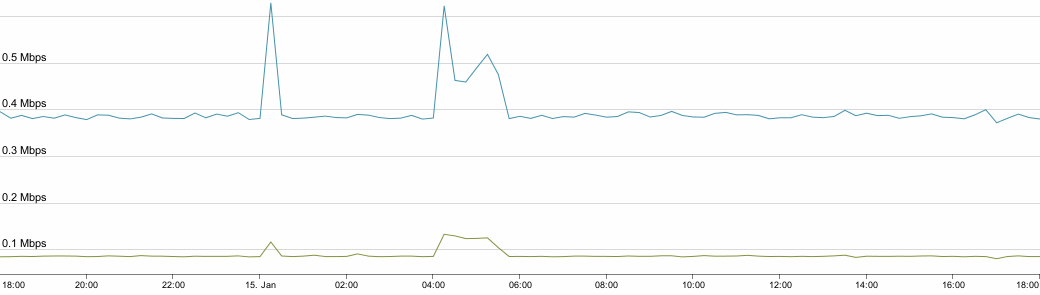
HP SIM Network Usage over 1d
Does it Matter?
If you’re trying to build an ultra high-performance network monitoring system, you will do everything you can to spread the polling load as evenly as possible. You will also ensure you are collecting only the bare minimum required. I haven’t shown the CPU load here, but clearly there will be collector system disk + CPU peaks associated with those network peaks, as it processes the returned data. If we are aiming to poll large amounts of devices from a single collector, we will need to spread the load as evenly as possible.
But what if your application architecture allows the easy deployment of multiple collectors, so you can spread the load? And in an age of cheap memory, who cares if we need to allocate a bit of extra RAM? If you look really closely at the graphs, you’ll see that we’ve still only got a few hundred kbps of network traffic, so that’s pretty much irrelevant.
But isn’t it just lazy?
Clearly there are advantages to spreading your polling load evenly. It does come with a development overhead, and you may need to be able to handle adjusting for small changes in polling windows - e.g. 295s one time, 305s the next. But what about the advantages of polling at set times (not just set intervals)? It turns out that it’s actually kind of handy to know exactly when the 15-minute poll will run. If you’re debugging a polling problem, or you’re monitoring some performance graphs closely to see if a problem is resolved, it’s actually really useful to be able to look at the clock and think “ah, the next 15-minute poll is due in 10 minutes.” It also makes your graphs much nicer - when comparing multiple metrics, the data points will line up nicely.
If you asked me about it 10 years ago, I would have said that you must design so that you spread the load as evenly as possible. These days? I might focus my development resources elsewhere, unless I was designing hyper-scale systems. I realise that of course hyper-scale (cloud/Big Data/Blah Blah) is very much the sexy thing right now, but you know what? It’s irrelevant to most of us, no matter how much you read. At the scale of a few hundred, or a few thousand monitored systems, it’s just not that big a deal any more. Make some effort to spread load if you need to, but don’t get too hung up on it, unless you’ve got data telling you otherwise.