ScienceLogic Architecture Overview
This is a basic overview of the ScienceLogic EM7 system architecture, describing the various components, their functions, and how they can be combined or split across multiple systems. I’ve been deploying ScienceLogic systems recently, so this blog acts as my own notes/summary.
The ScienceLogic system can be broken down into five functions:
- Database: Stores all configuration and performance data. The heart of the system.
- User Interface: Web interface, where users interact with ScienceLogic.
- Data Collection: Scheduled polling of monitoring systems, using SNMP, WMI, XML API, etc.
- Message Collection: Receive inbound SNMP traps and syslog messages.
- API: External systems can interact with ScienceLogic API, either to retrieve data, or to submit events and change configuration - e.g. Add new devices, change monitoring policies, etc.
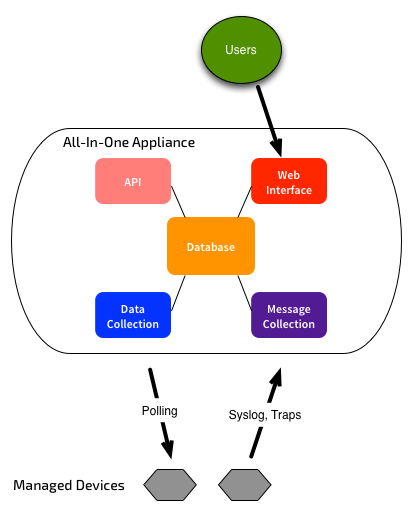
Where this gets interesting is that these functions can be deployed on one centralised servers, or spread out across multiple physical and virtual servers. You can run everything on one system, like this:
Or you could fully separate the functions across multiple systems:
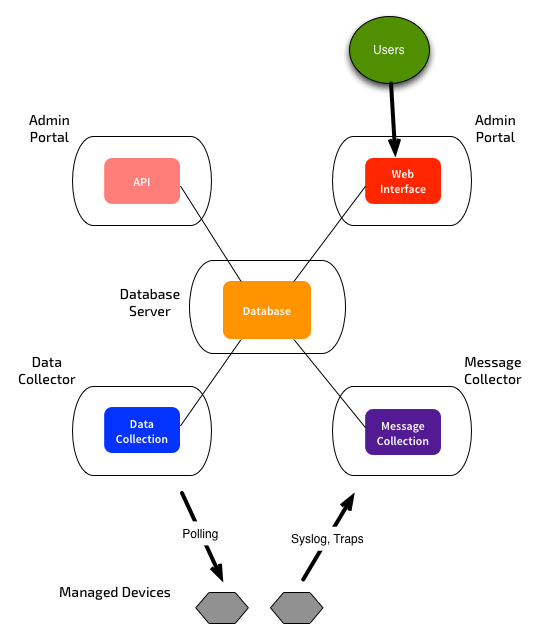
Note that there used to be a separate “Integration Server” for providing API functions. As of recent versions, this is no longer a dedicated system type - instead you can use an Administration Portal or Database Server.
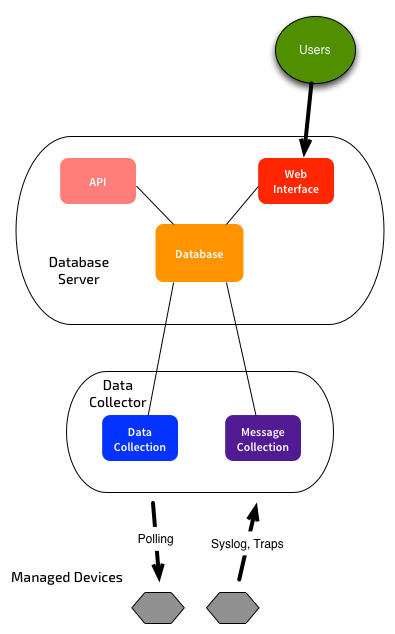
You could have some combination of the above components - e.g. Combine message & data collection on one system, and UI/DB & API on another:
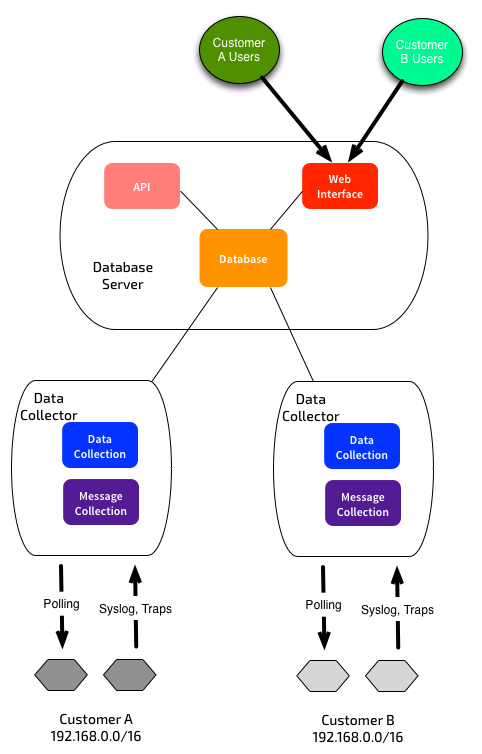
Splitting up configuration/data storage from collection lets you spread out your monitoring load, and/or work around challenges with network topologies, overlapping address space, etc:
All systems can be either physical or virtual, and all run the same code base. Splitting it across boxes does not significantly increase your administration overhead either. Patches are uploaded to the central server, and then deployed to all systems in one go. In theory, once you’ve set everything up, you shouldn’t need to manage any individual systems.
Check the “ScienceLogic Architecture” manual for more information about the architecture: HTML version, PDF version (Registration required; may need to be partner or customer. Yes it sucks that the documentation is behind a reg-wall).
The ability to break out systems, and spread load across multiple collectors provides us with more capabilities around HA, DR and scaling. I’ll take a look at those in a future blog post.