VMware EVC Mode
Recently I’ve been doing more VMware work. It’s been a while, but it makes a nice change. At this site, we have 100+ hosts, and thousands of VMs. Recently we were making some changes to the physical networking of some of the hosts, and we needed to evacuate all VMs from a host. But when we went to migrate the VMs, we got this warning:
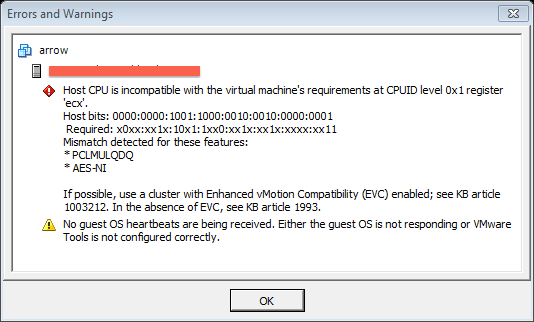
What’s it telling us? It’s saying that we can’t move that VM to that other host, because the CPU is incompatible. Apparently we need to use a cluster with Enhanced vMotion Compatibility (EVC) enabled. But this cluster already has EVC enabled.
What’s going on? And just what is EVC all about anyway?
Enhanced vMotion Capability (EVC)
Intel and AMD regularly update their CPUs. In the past it was all about clock speed, now it’s all about how many cores on one die. But it’s not just speeds that change - new features and new CPU instructions get released with each generation. Some of these features are fairly esoteric, but others are enormously important - e.g. the Virtualisation extensions. Operating systems and applications that can access the new instructions may be able to perform previously complex operations far more efficiently, or they may be able to access previously unavailable features. When a VMware ESXi host has newer CPUs, it can pass those capabilities on to any VMs hosted on that server. All older instructions and features are still supported, but newer ones can be exposed.
But what happens if you’ve got a VMware cluster with mixed CPUs? What happens if a guest is running on a newer server, and you vMotion it across to the older server? How can the guest OS handle it if the CPU suddenly changes?
That’s where EVC comes into play. Basically ESXi pretends that it has an older CPU. You choose what EVC mode you want, and what CPU architecture to pretend to have. All hosts in the cluster pretend to have the same CPU architecture - the only proviso is that all hosts must be able to support the same level. Then when a VM is launched, it will use that older CPU mode. It no longer matters which host in the cluster it runs on - they all support exactly the same features. No-one can use the new features, but at least you can move guests around the cluster. The idea is that you can now stagger your host upgrades. Once all hosts are running newer CPUs, you can change the EVC cluster mode if you wish.
When you change the cluster mode, it doesn’t affect any VMs until they are powered off, and restarted. Rebooting a guest OS is not sufficient - the VM must be stopped, then started. Any new VMs will immediately use the new mode. If you change the overall cluster mode, you can only raise the level if there are any VMs currently powered on, and using the current level. It’s easy to raise the level, but going back down is a pain, as all VMs need to be stopped. See this VMware KB article for more info.
So why did I see an error?
This was the odd thing. Our cluster was running in Nehalem mode. The CPU architecture supported Westmere (slightly newer). Given that the cluster was running in Nehalem mode, there should have only been VMs running in Nehalem or older modes (Penryn, Merom). Looking through the list of VMs, we had one running in Merom mode, over 100 running in Nehalem…and somehow we had 17 running in Westmere mode. Huh? How did we end up with VMs running in a newer mode than the cluster supported? I thought we only had backwards compatibility, not forwards compatibility?
We don’t know how we ended up in this scenario. Best guess is that these VMs were started at some point when the cluster was not using EVC. EVC was later enabled, and for some reason VMware let it get enabled, even though it could never work properly for those VMs. Because the underlying CPU architecture supported it, VMware let things keep running. It only got annoyed when we went to migrate the VMs. It never should have let us get into this position.
Solution - raise the EVC mode
All hosts in this cluster supported Westmere. We’re not planning on introducing any older hosts. The two options we had were either to stop and start each of those 17 VMs - painful, as they’re production systems - or to raise the overall cluster EVC mode. We went with the second option. As long as you’re raising the mode, it works without any problems. No outage to any systems. Only change is that those 17 VMs can now be migrated, as the destination host has the right EVC mode. Any new VMs will run with Westmere. Any existing VMs will just keep on running fine, with Nehalem mode. Since the new mode only takes effect on a full stop/start of the VM, they’ll probably continue running with that mode for years to come.
No restarts needed, with no outage == WIN.