SDN for Enterprise
SDN is the buzzword du jour in the networking industry, but it’s hard to make sense of what it might mean for “normal” people. Here’s my take on what SDN solutions & architectures might look like in the Enterprise space, and the problems that it could solve.
I often hear comments from Enterprise Network Managers that they don’t know what SDN’s going to do for them, or why they should bother looking at it. All the hype doesn’t seem to apply to “normal” businesses that have a few hundred staff, and < 1,000 virtual machines.
I believe that problems do exist with networks at that scale, and that SDN can help solve some of those issues. Rather than having to explain it repeatedly, I’ve decided to write it down.
Firstly, I see it as two semi-distinct areas: Campus/WAN, and Data centre. Obviously there is an integration point, but the two areas have different challenges. Since the problems are different, we’ll probably see different products & solutions for each area. These will probably merge in future.
I’m focused on what could be deployed today, or within 12 months. I expect to see some very different options available in 3-5 years as things settle down.
Campus/WAN
This is the traditional internal network, providing basic network connectivity services to users. Typically they’ll be concentrated in a few main buildings, with a number of smaller branch offices.
What does it look like?
These networks are generally fairly simple. Switch networks at each site are no more than two layers, with routed links between sites. Inter-site links are mostly delivered via Ethernet, with VPNs used for securing inter-site communications.
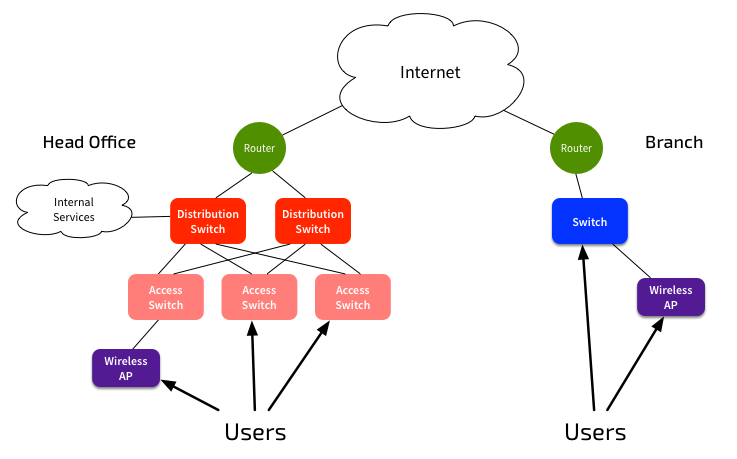
Users connect to the network, and get access to corporate systems, and the Internet. The internal network is also used for handling VoIP connectivity, and possibly CCTV from remote sites to a central point. Manufacturing organisations will also use the network for plant monitoring and control.
An increasing number of users connect via wireless, and users expect the same level of access, regardless of their connection method.
What are the challenges?
- User identification/Access control: Identifying users & systems, and controlling access based upon user identity. Should be same policy regardless of connection type, and ideally regardless of client type.
- Traffic control/manipulation: We still don’t have all the bandwidth we’d like. So we need to manipulate paths for specific traffic types, and prioritise some types of traffic. QoS is a nightmare to deploy in a cost-effective way, and it’s getting harder to identify specific traffic types with greater use of soft clients and encryption. Policy-Based Routing is only suitable for manipulating very specific flows, and is difficult to update.
- Security: Traditional IDS/IPS doesn’t scale in cost-effective way. We can’t afford to scan every single packet - need to choose specific packets to inspect.
- Configuration Management: controlling network device configurations, and being able to quickly roll out changes. Related problem: Visibility of actual traffic paths, including L2 and L3 hops.
The network elements will have at least a 5 year lifetime, and will be replaced in rolling upgrades. Since the network may have many elements, and be wide-spread, any software solution must not lock the network into a single hardware vendor. Enterprises made that mistake with EIGRP, and do not wish to repeat it.
SDN Architecture
Traditional routing and forwarding are not going away. But we need a central control point for our network, that shows all our paths, and gives us the ability to manipulate flows, without having to touch all the devices. The only standards-based method available to do that today is OpenFlow. So we need an OpenFlow controller to manipulate specific flows, with a default of regular routing & switching.
The controller must have well-defined APIs, and to make it practical for Enterprises, we need to be able to plug in new features or “applications” that extend capabilities. The controller must be able to interact with other systems, such as authentication and security systems. The network should be able to identify users, forcing them to authenticate if we don’t know who they are. Once authenticated, we should be able to apply policies to that traffic, regardless of how the user is connecting. We should then be able to redirect specific traffic flows to an IPS.
The controller should also be able to interact with applications, so that we can identify specific traffic types, such as VoIP or CCTV, and apply QoS policies.
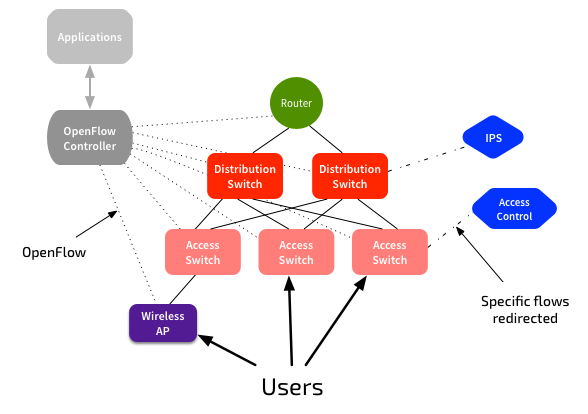
Example solutions here are OpenDaylight, or HP’s SDN Controller. But these are only one part of it - we need the applications that run on top of the controller, and in the security examples, we need the complementary security systems.
The architecture described above will solve most of the Enterprise’s challenges. The Configuration Management problem can in part be solved by most NMSes available today, but the addition of an OpenFlow controller should solve the path visualisation problem.
Even if Enterprises aren’t yet ready to deploy an OpenFlow controller, they should make sure that any network devices purchased today support OpenFlow 1.3. This will ensure future interoperability.
Data Centre
The traditional Enterprise data centre is more likely a small room with a few racks, than a huge Facebook-style data centre. But it runs the services they need, and they’re proud of it.
What does it look like?
Virtualisation has dramatically reduced the size of the traditional Enterprise data centre. This has dramatically reduced the physical network requirements. For most Enterprises, a pair of 32x40GbE switches will provide all the physical network connectivity they will need for thousands of VMs. Most Enterprises still have slightly more gear than this in their data centre, but it’s rapidly collapsing to this:
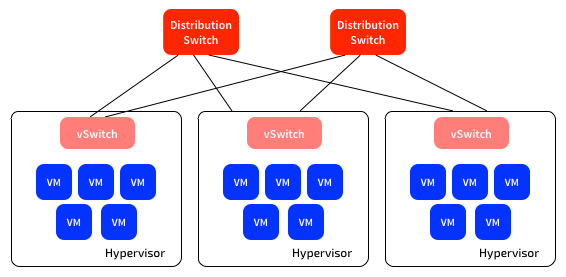
(There are more physical servers than I’ve shown here, but still only the two physical switches)
There are very few, if any physical servers left - almost everything is virtualised.
What are the challenges?
- Relatively few physical devices and non-blocking fabrics have made physical network far simpler. Primary problem is managing the virtual networking - and any hand-offs to the physical network. Less concerned about network hardware lock-in, due to low number of devices.
- Test and development environments have collapsed into the same physical layer as the production systems. Need to provision isolated test/dev networks quickly, and then get rid of them, without making physical changes
- Security requirements still exist, but no desire to deploy physical firewalls, etc. May even be impossible. Preference is to virtualise network services such as firewalls, load balancers, etc. Physical devices are proving difficult to scale cost-effectively, and managing large firewall rule-sets, or centralised load balancers is operationally difficult.
SDN Solution Architecture
I recommend the use of a virtual network overlay solution that tightly integrates with the virtualisation management system. This solves the problems of rapidly deploying networks (including test and development), without needing physical network changes.
The overlay solution must incorporate network services such as firewalls and load balancers. These must be able to be rapidly deployed, and distributed for performance. Deploying more, smaller systems helps with both performance and operational management.
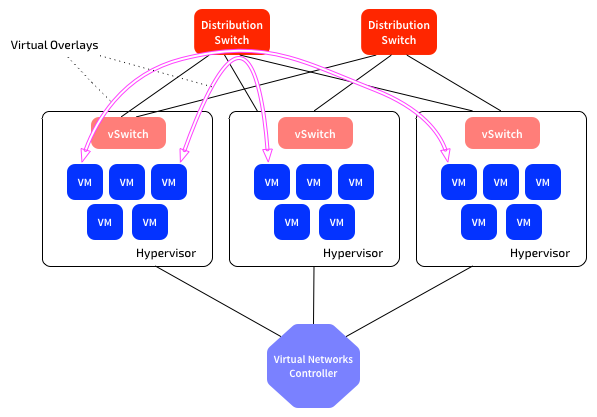
Most Enterprises are using VMware, so the obvious product example here is VMware NSX. Given the requirement for tight integration for the virtualisation management solution, the choice of hypervisor will decide the network virtualisation system. I hope we will see more alternatives in future, priced at a level that ‘normal’ Enterprises can afford. This will probably coincide with OpenStack becoming viable for ‘normal’ Enterprises.
Integration/Federation
The above models operate independently. Two systems, addressing different areas of the network. How much integration should there be between the two systems? Should there be an East-West federation between the control systems, or should there be North-South integration between these systems and something that sits over the top, and co-ordinates actions?
I believe we will see some degree of federation, for specific functions - e.g. Co-operation between the virtual overlay network controller and the physical underlay, as described in Elephant Flow Mitigation via Virtual-Physical Communication. This will be at specific touch points, where the domains overlap.
But beyond that I think the controllers will be communicating more North-South, with a broader system that sees more than just the network, but is also taking in data from applications, systems, users, etc. That platform will be orchestrating changes across the entire environment - or at least providing centralised visibility of what’s going on. Few Enterprises are in a position to do that today, but it is the general direction. As such, any network controller choices must support well-documented APIs, for future integration.
The Future
For the first 5 years of server virtualisation we simply took our physical servers, and replicated them as virtual machines, legacy devices and all. What the hell does a VM need a sound card for? It’s only recently that we’ve started moving towards new models - look at Microsoft’s Generation 2 Virtual Machines, and Open Source Docker.
The above network models offer us improvements for the next few years, but they’re not yet a truly radical shift in the way networks work. I haven’t yet figured out what the next step is, but I suspect it’s about getting more intelligence from the network itself - e.g. implement functions directly at the network layer, not sending traffic through virtualised versions of traditional devices. Hopefully we’ll see some truly different solutions emerge in the years ahead.