ScienceLogic Global Network Manager
ScienceLogic 7.5 includes many enhancements and new features. One I’m interested in is “Global Manager” which can be used to massively scale out the ScienceLogic architecture. Here’s some more detail on why ScienceLogic introduced this feature, and what it does.
Problem: A Single Database
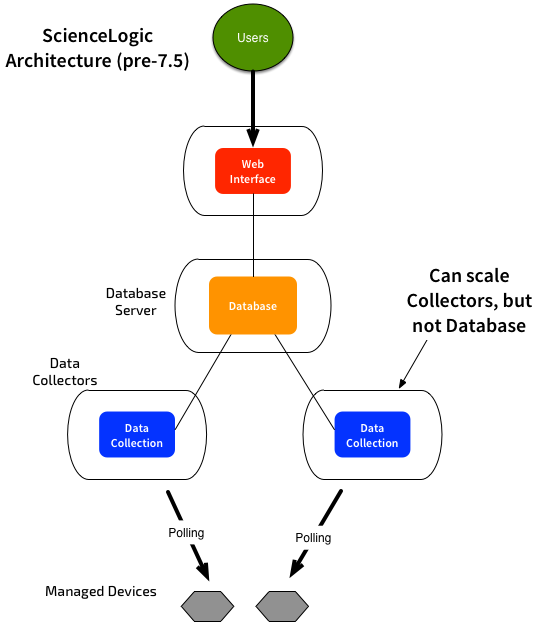
I’ve talked before about the ScienceLogic architecture, and noted that the Database can be a bottleneck:
You’ll notice that all the variations only ever have one “active” database at any one time. All the processing is done on this system, with the results replicated to the other databases. You can scale out your Collectors or User Interface by adding more servers – but you can’t scale out the core database. Right now you have to scale up the database – ie. allocate more RAM/CPU/IOPS. This gets around the performance bottlenecks, but comes at a cost.
In this diagram, we can see the database is at the heart of everything. We can have HA & DR options for it, but there is only ever one active DB:
Distributed Architecture
We can have multiple web interfaces, but they all query the same database.
Solution: More Databases!
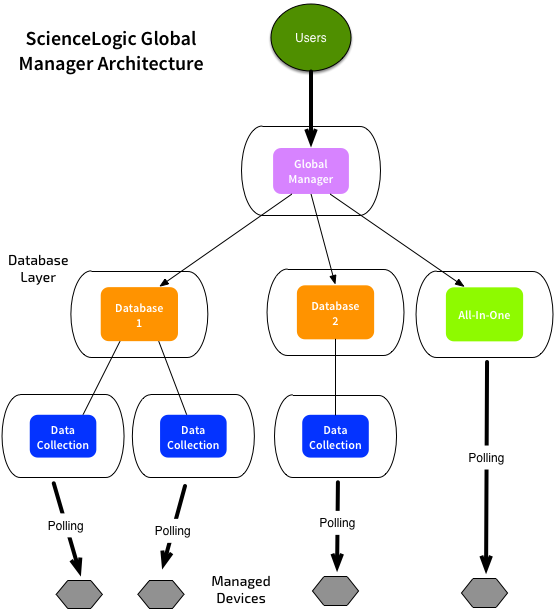
The new Global Manager option from ScienceLogic use a new “Global Manager” instance to query multiple databases:
Global Manager
When users login to the Global Manager, it uses the ScienceLogic API to query multiple database servers to retrieve data. Dashboard widgets can combine and display data from multiple sources, in a transparent way.
The individual databases are responsible for monitoring their own set of devices, via one or more collectors. The Global Manager can even communicate with “All-In-One” instances. So now both collection and processing can be distributed.
Currently this is “View Only” - the Global Manager system retrieves data, but it can’t push out configuration changes such as new monitoring policies.
Benefits of This Approach
- System scale is massively increased.
- Single-sign-on.
- Administration can now be localised. ScienceLogic offers multi-tenancy, but there are some limitations to breaking up administration.
- Databases can be fully separated for those security policies that need separate databases, not just access control for data separation.
Verdict
This looks like a good approach for scaling out ScienceLogic systems. There are still some limitations, but I expect to see further improvement. I’m also particularly happy that ScienceLogic is using standard APIs for this communications. This enforces API consistency and completeness, which helps our own customisations and integrations.