No Alarms May Not Mean No Problems
Network monitoring is often a reactive process. Engineers see an alarm, and take action. Alarms mean someone broke something, and it needs attention. Deal with the alarms, and all will be well. No alarms == Good. But every now and then no alarms means that monitoring is broken. Here’s an example of where this happened, and what I do about it.
Situation: A Tenuous Chain of Monitoring
This situation has several monitoring systems strung together. HP Command View is monitoring some storage arrays. It forwards alerts to HP SIM, which forwards high priority alarms to ScienceLogic:
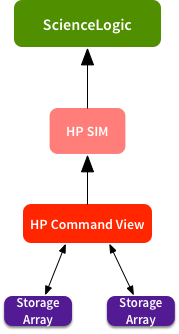
Any time you get a long chain like that, there’s a high chance of failures. It only takes one thing to break, and you stop receiving alarms at the top level. HP SIM guarantees stuff will break. Failures tend to be silent - you find out that monitoring is broken weeks after the fact.
So How to Identify Failures?
The trick I used here was to configure ScienceLogic to poll for the date of the last received alarm. I then set thresholds to alarm if the last alarm was more than 2 days, 4 days, or 7 days ago. We usually received a low-priority alarm every couple of days, so this balanced false positives with missed alarms. Now we can get notification of broken monitoring within a few days at most.
Later releases of the HP Command View software added a “heartbeat” function that sends traps on a periodic basis. I set this up to send a trap once an hour. This trap gets logged as a “Healthy” alarm - its only function is to reset the timer for the last received alarm.
Validation!
Sure enough, a few days ago I started getting some alarms saying “Last event received from XXXX 2 days ago.” I dug into it, and found that there had been changes at the Command View level, and it was no longer forwarding events. If I hadn’t configured that catch-all monitoring, it could have been weeks before I found out. Success!
I don’t recommend doing this level of monitoring for everything. But you should be periodically looking at all systems, and identifying those systems raising the fewest alarms. You might be missing something.